词向量
词的分布假说:词的特征由其上下文决定。  词向量又称词嵌入(word embedding),把词映射到某几个特征构成的低维向量。embedding在数学上表示一个映射,该映射是单射的(每个Y只有唯一的X对应,反之亦然)、结构保存的(比如在X所属空间上X1<X2,那么映射后在Y所属空间上同样Y1<Y2)。
词向量又称词嵌入(word embedding),把词映射到某几个特征构成的低维向量。embedding在数学上表示一个映射,该映射是单射的(每个Y只有唯一的X对应,反之亦然)、结构保存的(比如在X所属空间上X1<X2,那么映射后在Y所属空间上同样Y1<Y2)。
工具word2vec可训练词向量。skip-gram从中心词预测周围词,CBOW从周围词预测中心词。 
skip-gram
对每个单词,计算与前后各m个邻近词共同出现的概率积J’(θ)。loss函数用负对数似然估计J(θ)。  与邻近词\(u_o\)共同出现的概率\(p(o|c)\)用softmax表示,其中\(u_o^Tv_c\)是邻近词\(u_o\)与中心词\(v_c\)的相似度。
与邻近词\(u_o\)共同出现的概率\(p(o|c)\)用softmax表示,其中\(u_o^Tv_c\)是邻近词\(u_o\)与中心词\(v_c\)的相似度。  Lecture2课件有梯度\(\frac{\partial{J(θ)}}{\partial{v_c}}\)的推导过程。
Lecture2课件有梯度\(\frac{\partial{J(θ)}}{\partial{v_c}}\)的推导过程。
Midterm Review有skip-gram例子讲清楚过程。 
cbow

glove
skip-gram用梯度下降法逐步计算了单词之间共同出现的概率。还可以用个全局矩阵记录单词之间在一定窗口内共同出现的次数,GloVe利用了这一信息。 
词窗口分类
利用前后各m个邻近词,把中心词在几个歧义中的分类。
RNN是基础构件
RNN有一个内部状态\(h_{t-1}\)、待训练参数\(W=\begin{bmatrix} W^{(hh)} & W^{(hx)}\end{bmatrix}\),每次读取输入\(x_t\),更新\(z_t=W^{(hh)}h_{t-1}+W^{(hx)}x_t=\begin{bmatrix} W^{(hh)} & W^{(hx)}\end{bmatrix} \begin{pmatrix}h_{t-1} \cr x_t\end{pmatrix}, h_t=g(z_t)\)。
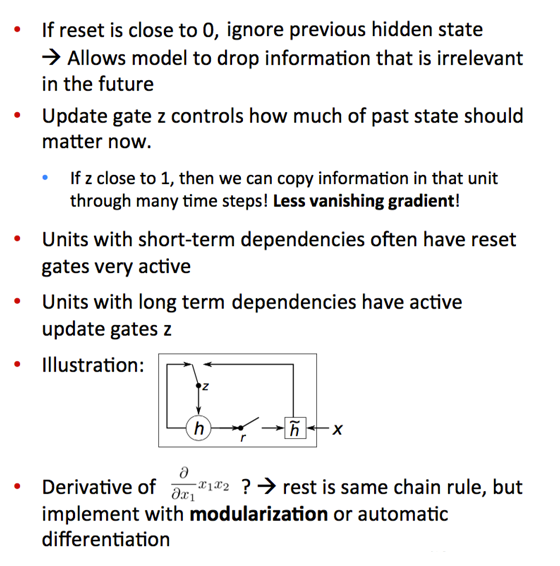
RNN网络深度较大,因链式求导不断相乘,有梯度消失或爆炸的问题。GRU和LSTM缓解了梯度消失问题,是常用的RNN。
GRU, Gated Recurrent Unit
\(h_t=gru(x_t, h_{t-1})\) \(\tilde{h}_t\)是候选更新,update gate \(z_t\)决定新状态中旧状态和候选更新所占比例,reset gate \(r_t\)决定候选更新中保留多少旧状态。 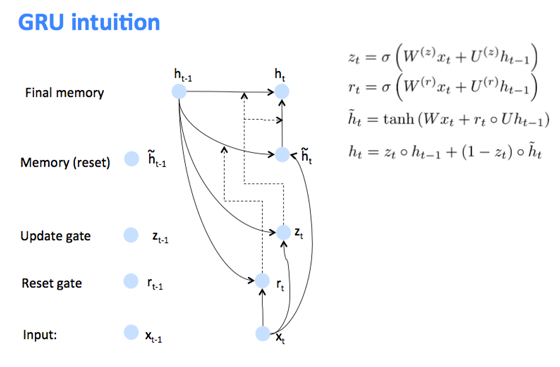
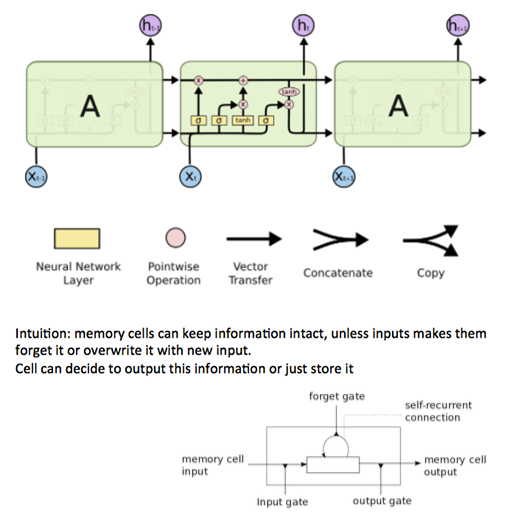
LSTM, Long Short Term Memory
\(h_t=lstm(x_t, h_{t-1})\) 
神经机器翻译
语言模型计算整个单词序列的概率\(P(w_1,…,w_r)\)。
由两个RNN分别作encoder(蓝色)和decoder(红色)。由于只记住encoder最后状态Y,翻译长句子时效果不好。 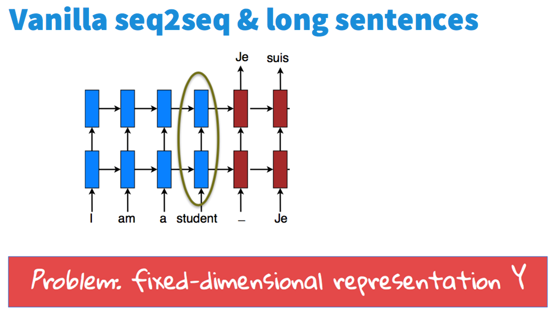 Attention的想法是多记住一些源状态。
Attention的想法是多记住一些源状态。 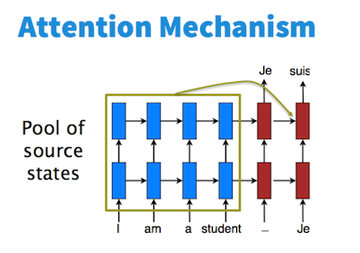 decoder算\(h_t\)时,先算\(h_{t-1}\)与各源状态的相似性得分,用softmax将得分转成概率(这概率就叫attention),再加权相加各源状态得到上下文向量\(c_t\),用\(c_t\)计算\(h_t\)。
decoder算\(h_t\)时,先算\(h_{t-1}\)与各源状态的相似性得分,用softmax将得分转成概率(这概率就叫attention),再加权相加各源状态得到上下文向量\(c_t\),用\(c_t\)计算\(h_t\)。 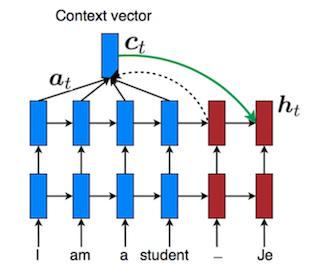
CNN
词向量拼接成长向量,长为h词的滑动filter作卷积算\(c_i\) 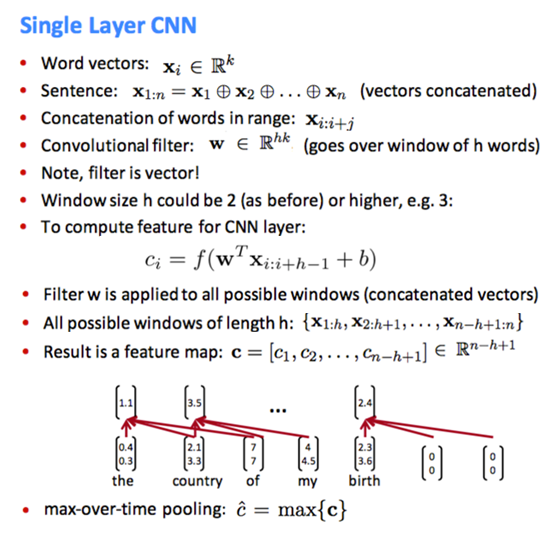
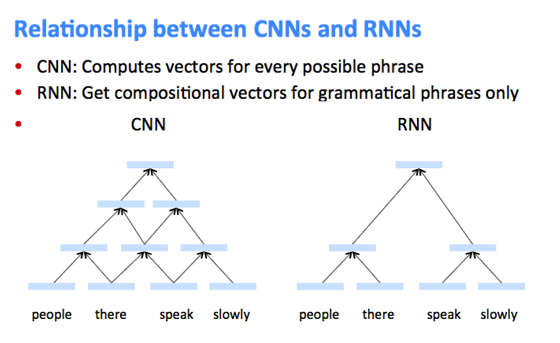
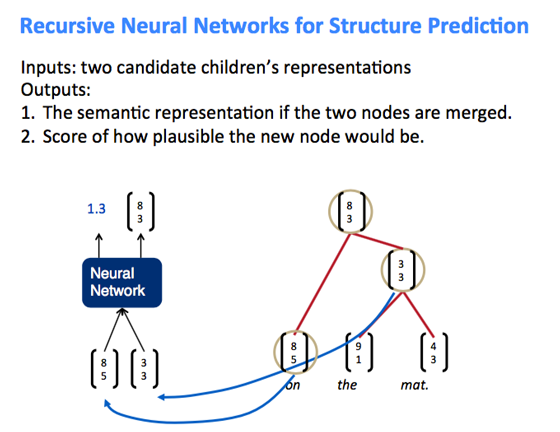
TreeRNN, Tree Recursive Neural Network
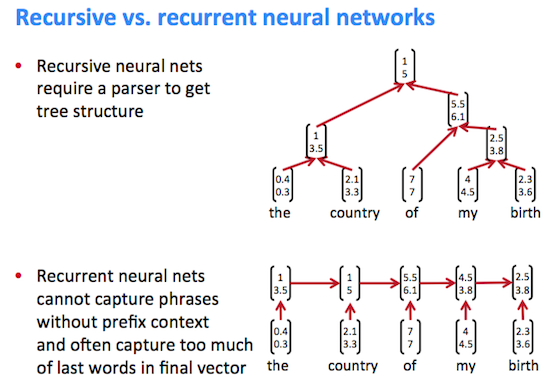
结构预测:将相邻两节点用神经网络算合并分数,取得分最高的合并出新节点。