重要的基础库
numpy
多维数组对象ndarray,向量化数组运算,线性代数运算、傅里叶变换、随机数生成
作为算法之间传递数据的容器,numpy数组对数值型数据的存储和处理要比python内置的高效
pandas
Series是一维数据及其索引,类似数组(整数索引)或定长有序的字典
DataFrame是二维表格,既有列索引又有行索引
scipy
解决科学计算中各种标准问题的一组包,主要包括:
- integrate:解微积分方程
- linalg:扩展了由numpy.linalg提供的线性代数运算、矩阵分解功能
- optimize:函数优化器(最小化器)、根查找算法
- signal:信号处理工具
- sparse:稀疏矩阵和系数线性系统求解
- special:许多常用数学函数(如伽玛函数)
- stats:连续或离散概率分布(如密度函数、采样器、连续分布函数)、各种统计检验方法、描述统计法
- weave:利用内联c++代码加速数组计算
iPython环境
粘贴剪贴板内容用%cpaste
输入行In[X]的文本保存在_iX变量中,输出行Out[X]的文本保存在_X变量中,最近两个输出结果保存在_(一个下划线)和__(两个下划线)变量中
可与系统shell交互:output = !cmd $arg
算语句执行时间用%timeit
使对象在Out[]输出时更有意义,给类加上__repr__方法
NumPy基础
arr.shape说明数组各维度大小,arr.dtype说明数组数据类型
np.arange(n)产生[0,n)序列
np.reshape((m, n))重排成m行n列数组
切片和索引
ndarray切片是原数组的引用,切片上任何修改都会直接反映到原数组上。这跟python数组切片总是复制数据不同。要想获得ndarray切片的副本需要显式地复制,如arr[5:8].copy()
arr[i,j]等价于arr[i][j];多维数组中,若省略了后面的索引,会返回维度低些的ndarray
布尔索引:索引中的数组作比较运算,将得到一个布尔数组作为索引。多个布尔数组可以使用 与&、或|、非- 运算。将创建数据的副本。
花式索引:用整数数组或ndarray作索引。将创建数据的副本。
使用np.ix_函数选取矩形区域,如arr[np.ix_(rows, columns)]
np.where(cond, xarr, yarr)是if cond then xarr else yarr的向量化缩写
arr.sort()就地排序,np.sort(arr)返回排序副本
线性代数
mat.T转置
matA.dot(matB)矩阵相乘,奇怪的命名!
solve解Ax=b,其中A为方阵
lstsq求Ax=b的最小二乘解
pandas入门
由字典构造DataFrame时,字典一项变为DataFrame一列
索引
DateFrame相关参数中columns索引列,index索引行
frame[]式索引:
- 用标签是取列(标签切片是闭区间)
- 用数字切片或布尔数组是取行
- 用布尔DataFrame是取元素
frame.ix[]选取行列:
frame.ix[rows, columns]选取行和列,ix是index缩写frame.ix[rows]选取行frame.ix[:, columns]选取列
由整数索引的pandas对象,根据整数选取数据的操作总是面向标签的,这也包括用ix进行切片
默认axis = 0按行,一行行操作或所有行聚合;axis = 1按列,一列列操作或所有列聚合
sort_index()排序:
frame.sort_index()按行标签排序frame.sort_index(axis = 1)按列标签排序frame.sort_index(by=['a','b'])按某些行列的值排序
combine_first(frame1, frame2),先从第一个对象中取值,不行就再去第二个对象中取值
层次化索引,一个轴上有多级索引。swaplevel(level1, level2)互换两个级别,sortlevel(level)根据某级别的值对数据排序。
set_index()将某些列转换为行索引,reset_index()将行索引转换为列
stack将列索引旋转为最内层行索引,unstack将行索引旋转为最内层列索引
pivot透视
将只分一些列名不断append的“长格式”,转换为以某列值为行索引的“宽格式”
frame.pivot(作为行索引的列名, 作为列索引的列名, 作为单元格的列名); 如果忽略最后一个参数,frame.pivot(作为行索引的列名,作为列索引的列名),其他列会分别作为外层列索引得到一个个DataFrame,这些DataFrame一个个横向拼接起来,得到带两层列索引的DataFrame
其实,pivot只是一个快捷方式:用set_index创建(行索引名, 列索引名)的两层行索引,再用unstack将内层的(列索引名)转回成列索引
groupby是一个 拆分-应用-合并 的过程:将数据根据特定轴的一个或多个键拆分为多组,在分组上应用函数产生一个新值,将所有分组的结果合并
pivot_table按行列分组聚合,对比pivot是只分组不聚合
crosstab按行列分组计数,是特殊的pivot_table
以时间戳(字符串或datetime对象)为索引的Series就是时间序列,有多种时间选择方式
画图入门
matplotlib是基础
在Figure的subplot上绘图
画线时,颜色(k黑r红 等,或#rgb值)、标记(o圆x叉 等)、线型(--虚线.点线 等)
seaborn接口更高级
scikit-learn
模型验证
5-fold cross-validation 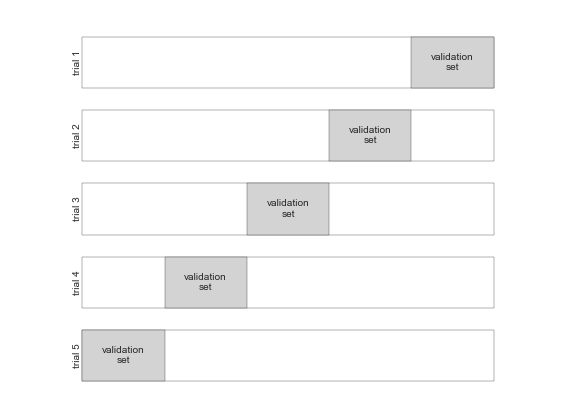
模型复杂度 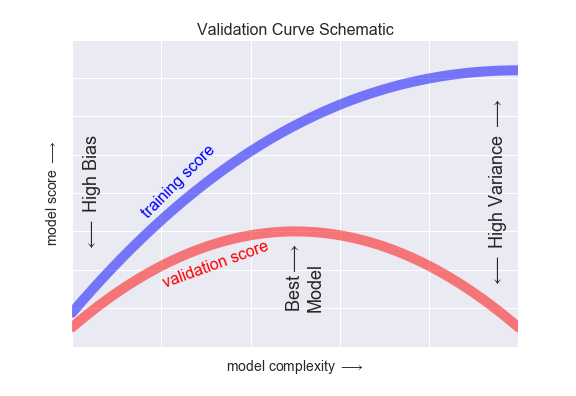
注意:训练效果总是好于预测效果
high-variance模型的样本大小 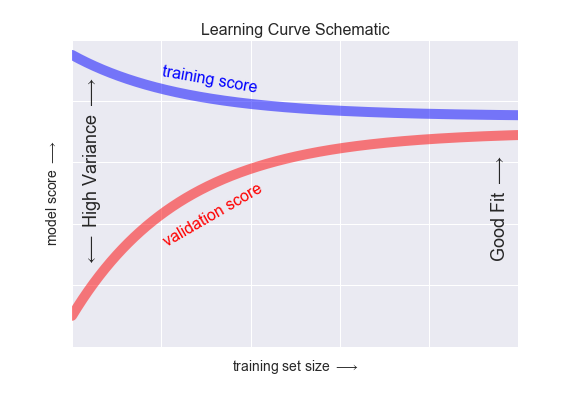
常用模型
naive bayes 的 的naive就naive在 要先假设样本属于某个特定分布,最终的分类效果也只是趋于这个分布,常作为分类任务的初始尝试
简单线性回归 \(y = a_0 + a_1x_1 + a_2x_2 + a_3x_3 + ...\),常作为回归任务的初始尝试
多项式回归 \(y = a_0 +a_1x + a_2x^2 + a_3x^3 + ...\),可使用线性回归库计算,只要根据\(x_n = x^n\)先把输入\(x\)变换成 \(x, x^2, x^3, ...\)。其他非线性回归类似,只要根据\(x_n = f_n(x)\)先把输入\(x\)变换即可。
参考
- 《利用Python进行数据处理》
- Python Data Science Handbook
- Python Numpy Tutorial