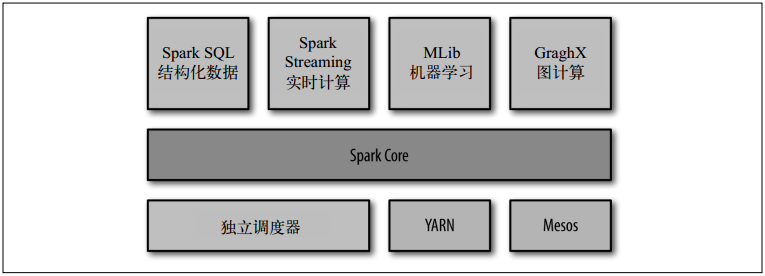
Spark软件栈构成个集群计算平台。SparkCore对运行在集群上的由很多计算任务组成的应用进行调度、分发和监控。
Spark对数据的抽象叫RDD(Resilient Distributed Dataset,弹性分布式数据集),是不可变的分布式对象集合,叫“弹性”是因为任何时候都能重算。RDD分成多个分区,分别运行在集群的不同节点上。RDD支持两种操作:transformation和action。转化操作由RDD生成新RDD,如map()和filter(),惰性求值,即第一次在行动操作中用到时才真正计算。行动操作对RDD计算一个结果,如reduce(),默认每次都重新计算RDD,除非RDD显式持久化,默认持久化到JVM堆空间。
键值对RDD就是Java的Tuple2或Python的元组,可支持操作reduceByKey()、groupByKey()、join()、sortByKey()、countByKey()等
Spark支持多种输入输出源:
- 本地或分布式文件系统:文本文件、JSON、CSV、SequenceFiles(用于键值对数据的Hadoop文件格式)、Protocol Buffers、Java序列化出的对象文件
- Spark SQL:Hive支持的任何表(Apache Hive是Hadoop中常见的结构化数据源)
- JDBC数据库、Cassandra、HBase、elasticsearch
参考
- 《Spark快速大数据分析》